
Голосовой интерфейс — это либо гениальная технология, время которой, наконец, настало, или самая бесполезная трата времени со времен ботов, блокчейнов или игрофикации.
На самом деле всё не так драматично. В настоящее время нам, для использования и разработки, доступен новый интерфейс ввода-вывода, и самое полезное, что могут сделать дизайнеры, это понять, когда и как его правильно применять.
Конец начала
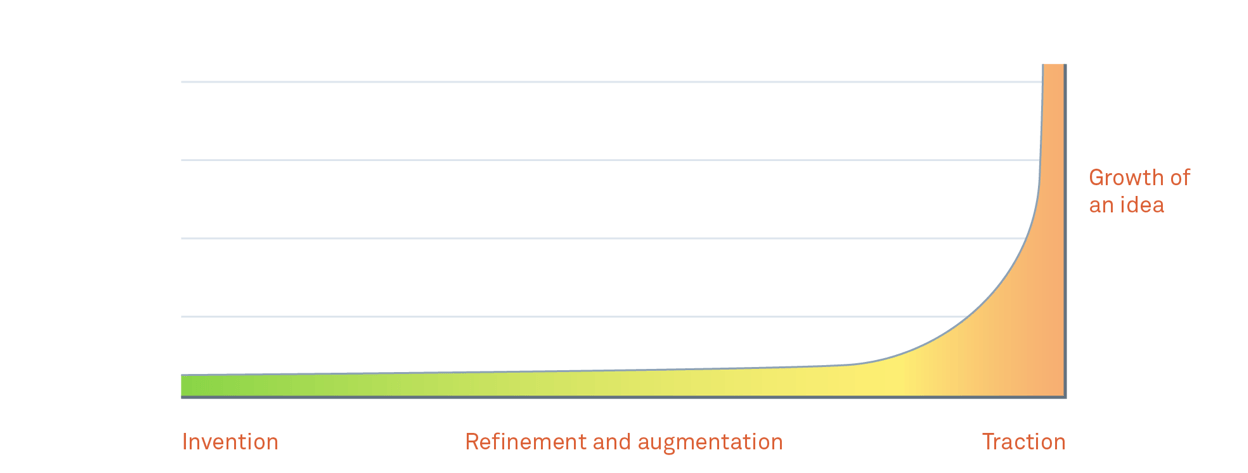
Недавнее появление Alexa, Siri, Cortana и «Okay Google» не означает, что время голоса «наконец настало». Скорее это значит, что мы «наконец» начали идти в этом направлении. Завершился этап демонстрации, шумихи, и больших обещаний. Теперь, голосовой UI превратился в технологию, поддерживающую реальные случаи использования.
Существует определенная дорога, по которой должна пройти каждая новая технология. Билл Бакстон, глава отдела исследований в Microsoft Research, видел появление всех новых интерфейсов, и говорит о том, что путь технологии от исследовательского проекта до «полного взросления» занимает примерно 30 лет.
Так что обычно, этот процесс занимает какое-то время, и когда наступит момент полной реализации технологии, нельзя ожидать, что она завоюет абсолютно все механизмы ввода, но она будет их дополнять.
Замещение — редкий случай
Новые системы ввода не замещают своих предшественников, они работают вместе с ними. Голос не заменит сенсорные технологии. Сенсорные технологии не заменили мышь. Мышь не заменила командную строку. Аналитики жаждут простой истории, где рождение каждой новой технологии мгновенно предвещает смерть предыдущей, но интерфейсы по своей сути являются мультимодальными. Чем больше, тем лучше. Каждая новая технология начинается в новой, необслуживаемой нише, затем она медленно расширяется, пока не найдет все области, для которых она лучше всего подходит. А у голосовых интерфейсов есть отличная ниша.
Placeona

Билл Бакстон представил концепцию «Place-ona» (от persona, с заменой первой части слова на place (место)), применяющую концепцию персон, для того, чтобы показать, каким образом место вашего нахождения накладывает ограничения на возможные взаимодействия (далее «персона»). Не существует лучшего способа ввода или вывода. Всё зависит от того, где вы находитесь, что в свою очередь определяет то, что вы можете использовать.
На очень простом уровне, люди имеют руки, глаза, уши и голос. Давайте взглянем на реальные сценарии:
- У персоны в наушниках в библиотеке будут свободны руки, глаза, уши, но на нее будут наложены голосовые ограничения
- У занимающейся готовкой персоны будут грязные руки, свободные глаза, уши, и голос
- У персоны в ночном клубе будут свободные руки, глаза, но она не сможет говорить и слышать из-за громкого звука.
- У персоны за рулем будут заняты руки, глаза, но свободны руки и голос
Основываясь на этом, можно увидеть в каких сценариях будет полезен голосовой интерфейс, и его общую роль как механизма ввода.
Но этот интерфейс такой медленный и забагованный!
Со скоростью и точностью голосовые UI справляются намного хуже, чем другие пользовательские интерфейсы. Да, мы говорим быстрее, чем печатаем, но даже самая продвинутая технология обработки звука будет просить нас говорить медленнее, и тем не менее будет допускать ошибки. Во-вторых, прослушивание происходит гораздо медленнее, чем чтение, особенно прослушивание цифрового голоса. Мы можем просматривать, пропуская части текста намного быстрее, чем мы бы его прослушивали. Именно поэтому Visual voicemail был таким хитом.
Теперь становятся понятны две вещи:
- Голос — это нестандартный механизм ввода-вывода.
- Существует множество сценариев, в которых голос подходит лучше всего.
До каких пределов могут развиться голосовые интерфейсы?
Этот вопрос задавался на множестве конференций, и ответ всегда начинался с «всё зависит от…», но мне кажется, что нужно задавать более конкретные вопросы:
Насколько часто голос оказывается предпочтительнее, чем стандартные механизмы ввода?
Сегодня кажется, что голос хорошо зарекомендовал себя в автомобилях и домашних медиа центрах, но сколько появится других вариантов, и будут ли они вести к увеличению продуктивности, или останутся такими же казуальными? Захотят ли люди когда-нибудь прослушивать свои письма через AirPod?
Как серьезно может развиться обработка звука и когда это произойдет?
Большая часть населения планеты способна говорить быстрее, чем печатать, но сегодняшние технологии не могут поддерживать такую скорость обработки. Когда это изменится?
Когда стартует настоящий мульти-месседжинг?

В то время, как большинство сегодняшних мессенджеров поддерживают отправку асинхронных голосовых сообщений, они требуют, чтобы сообщение принималось в том же виде, в котором было создано. Пользователи должны согласовывать среду общения, которая может не работать, если они находятся в разном контексте. Это ведет к тому, что я называю «библиотечно-водительская проблема»: если Элис находится рулем, а Мишель в библиотеке, то как им общаться?
Элис за рулем, так что она не может использовать руки или глаза, а Мишель не может говорить или вообще создавать какой-либо шум в библиотеке. В идеальном мессенджере, пользователи должны иметь возможность создавать сообщения так, как им захочется, и получать их в любом, удобном для них формате.
Внесение голосовых технологий в повседневный месседжиг будет представлять из себя переломный момент, нормализующий мысль о людях, говорящих со своими гаджетами, с целью управления ими.
Ни платформа, ни парадигма…
Пока голос не является платформой или UI парадигмой, он остается новым интерфейсом, в среде которого, и для развития которого, мы должны работать. В противном случае, мы рискуем походить на людей, которые критиковали мышь во время ее появления.
Перевод статьи Деса Трэйнора

